.gif?width=1280&height=720&name=Shelf%20Count%20-%20Demo%20Days%20(1).gif)
Real-World Example: Retail Computer Vision
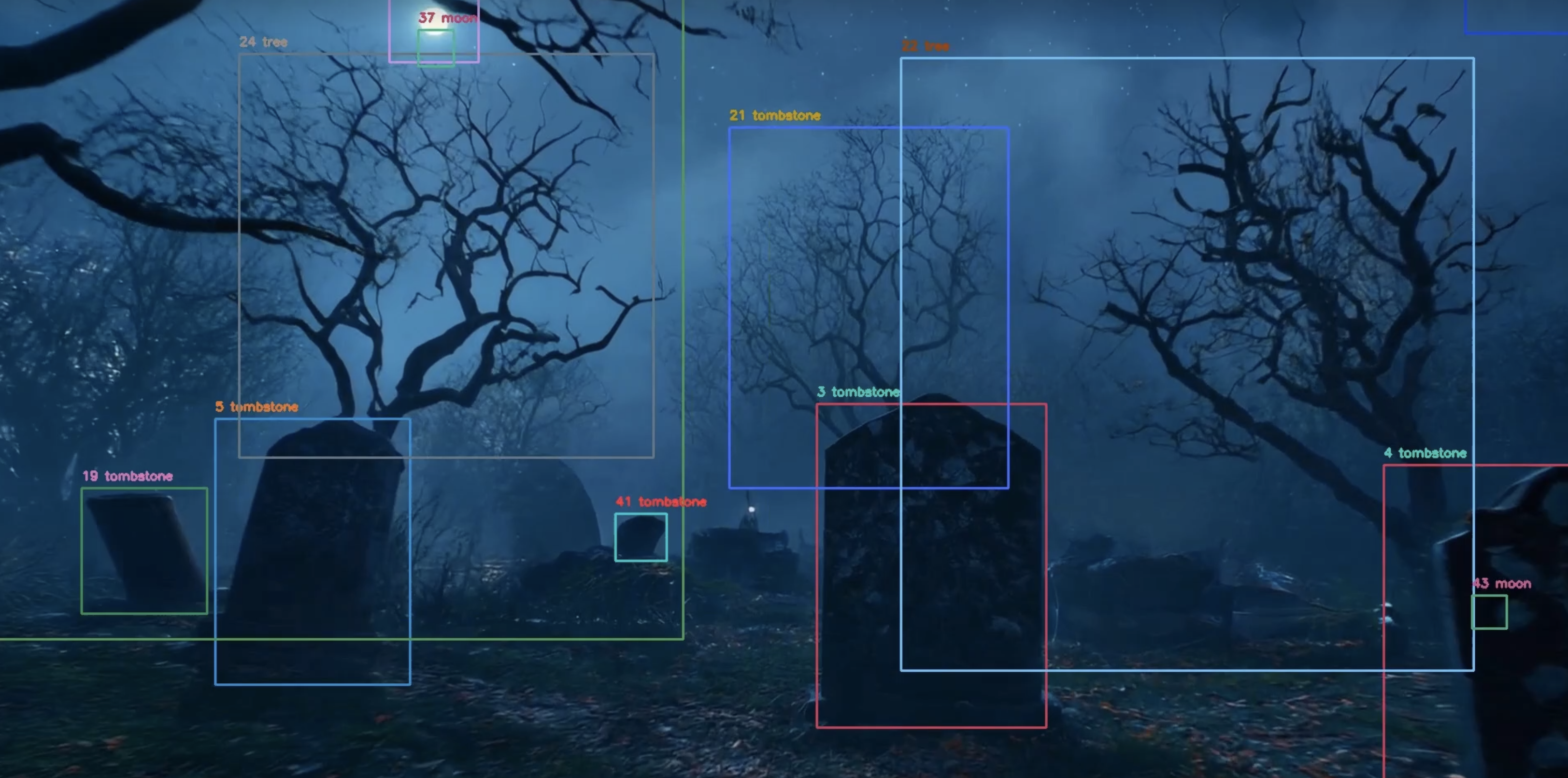
For example, a retail company is using computer vision to monitor product inventory. Initially, the system is functioning properly, detecting bare shelves with 95% accuracy. After new packaging designs and displays are introduced, the system begins to misidentify products.
By utilizing an extensible retraining pipeline, the company can:
- Collect new video samples automatically from stores
- Filter and annotate relevant images showing packaging or display updates
- Retrain models efficiently with cloud or hybrid compute infrastructure
- Deploy new models to all stores with minimal downtime
Within weeks, the system's accuracy is restored to 96%,the pipeline continuously tracks model performance and automatically retrains models when performance drops, ensuring consistent accuracy and reliability.
Not only is performance restored but also the company can scale its computer vision application to hundreds or thousands of locations.
Best Practices for Scalable Computer Vision Retraining
Automate Where Possible: Retraining is tedious and prone to human error. Automate data ingestion, labeling, and training triggers to maintain performance at scale.
Prioritize High-Impact Data: Data is not all created equal. Prioritize edge cases or situations where models perform worst.
Monitor Continuously: Monitor model accuracy, error rates, and other drift metrics to know when retraining is needed.
Leverage Incremental Learning: Update models incrementally without full retraining cycles to save resources.
Offer Reproducibility: Use version control over datasets and models to provide reproducible outcomes and facilitate audits.
Build Vision AI Better with Plainsight
In computer vision, deploying a model is only the beginning. Real-world conditions constantly change, and models that fail to adapt can quickly lose accuracy. Scalable model training and retraining pipelines are essential to keep AI systems reliable and adaptive.
With scalable infrastructure, automated workflows, and continuous monitoring, organizations can transform computer vision from a static tool into a living, evolving system.
The Plainsight Platform offers custom models and filters to train on a large scale, with retraining capabilities to update models based on incoming data. It intelligently balances cost and performance, automating retraining only when data drift is detected or accuracy thresholds are breached, ensuring efficient use of resources. By automating retraining and integrating continuous feedback loops, Plainsight ensures your computer vision model will scale with you.
Explore the Plainsight Platform and see how your vision AI can evolve in real time.
ChatTag: Bringing ChatGPT Vision to Image Annotation in OpenFilter
.png)
What is Infrastructure & Why is it Important?

No Comments Yet
Let us know what you think