
%20(4%20x%202%20in)%20(1080%20x%201080%20px)%20(300%20x%20300%20px)%20(1).png?width=100&height=100&name=OpenFilter%20Logo%20Options%20(4%20x%204%20in)%20(4%20x%202%20in)%20(1080%20x%201080%20px)%20(300%20x%20300%20px)%20(1).png)
OpenFilter Plus
Commercial support for the world's most popular open source computer vision workload management framework.
.png?width=100&height=100&name=license%20plate%20detection%20(10).png)
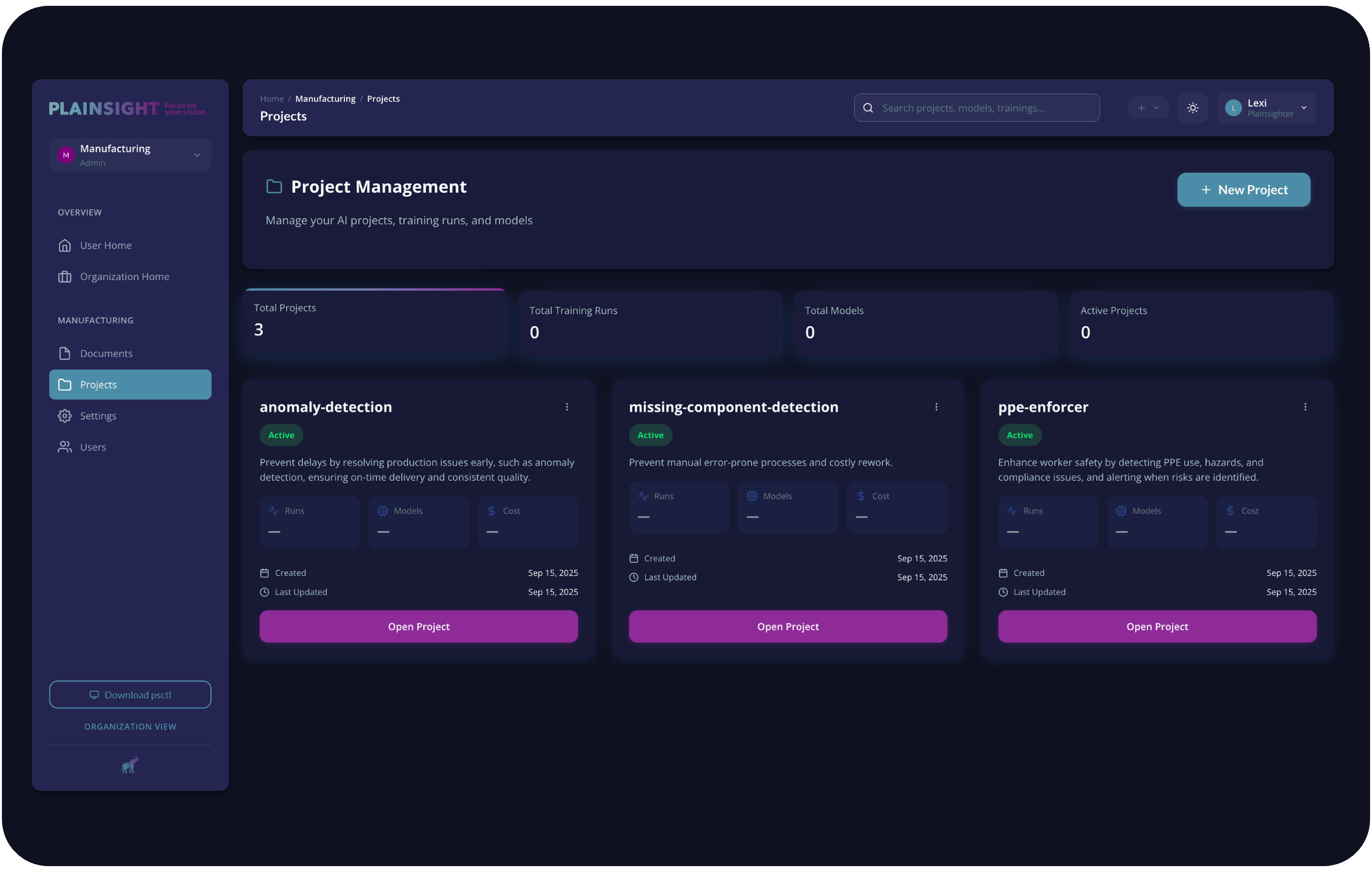
Plainsight Platform
Platform for managing the entire computer vision lifecycle and vision pipelines, from data collection and model training to deployment and monitoring.
%20(10).png?width=1075&height=605&name=Ad%20%20Gen%20AI%20Atlas%20Newsletter%20(888%20x%20500%20px)%20(10).png)